







Our team was intrigued: could an AI reviewer save us time and improve code quality in our workflow? To find out, we pitted several AI PR review tools against each other in a real-world scenario.
Before we dive in: I code well, but I write like a donkey—so I asked GPT-4.5 to turn our hands-on research into an easy-to-read blog post.
Our environment was a Vercel Turborepo-based monorepo that contains a bit of everything – TypeScript packages, React applications (with ShadCN UI components and Tailwind CSS), and even a Python app. We weren’t just interested in if these tools work, but how they handle the quirks of our codebase. Do they nitpick formatting or actually catch tricky bugs? Are they helpful sidekicks or noisy backseat drivers?
In this post, we’ll share our hands-on experience with four AI PR reviewers: CodeRabbit, devlo, GitHub Copilot, and Ellipsis (YC W24). We’ll cover what each did well (or not so well), which one emerged as our favorite, and toss in a few honorable mentions of other AI review tools worth watching. (And don’t worry – we’ll keep it technical, but with a dash of humor. After all, even code review bots appreciate a good dad joke now and then
After running these tools on several PRs, we gathered some high-level impressions of each. Here’s how CodeRabbit, devlo, Copilot, and Ellipsis fared in our monorepo showdown:
Key Takeaways from Each Tool
CodeRabbit
CodeRabbit made a strong first impression when it came to enforcing code standards and style consistency. It diligently pointed out lint issues, formatting inconsistencies, and naming deviations. In a way, it felt like an automated ESLint+Prettier on steroids – if a variable name didn’t match our conventions or a file’s structure was off, CodeRabbit caught it. This was great for keeping our TypeScript/React code style on point.
However, CodeRabbit showed some weakness in catching deeper implementation bugs. It occasionally missed logical errors or subtle bugs in the code’s logic. For example, in one PR a function’s edge-case (handling an empty input) was flawed – our human reviewers caught it, but CodeRabbit was oddly silent, having been more concerned about a missing JSDoc comment. It seems CodeRabbit stays within the lines of the PR diff and focuses on what it can easily lint. If a potential issue involved understanding context outside the PR or a cross-module interaction, it often glossed over it. Bottom line: great for polish and consistency, but don’t expect it to be a full-fledged bug detective.
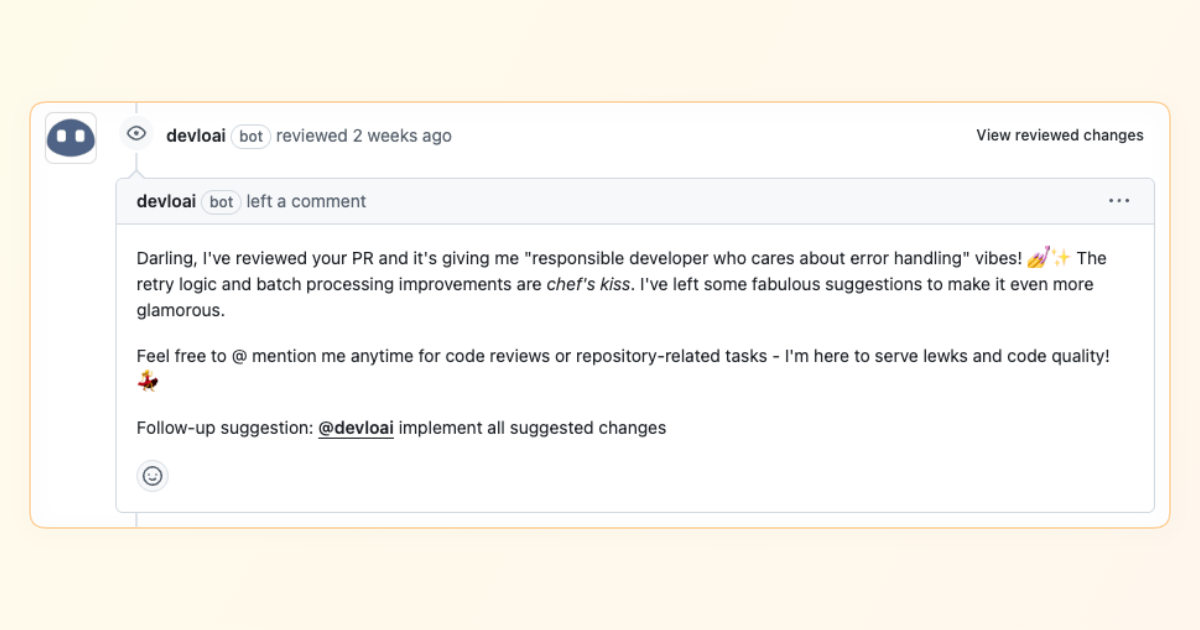
devlo
The devlo AI reviewer was like an enthusiastic teammate who had just finished a software architecture course. It provided insightful suggestions – often going beyond surface-level comments. In several instances, devlo not only flagged a potential problem but also suggested a clever solution or a best practice. For instance, it spotted an inefficient loop in our Python module and suggested using a generator for better performance. These kinds of value-added comments made us feel like devlo was really reading and understanding our code, not just pattern-matching common issues.
The flip side was that devlo could be noisy with excessive comments. It had a lot to say… about everything. Minor issues, stylistic preferences, even things that were arguably subjective got comments. Our PR discussion threads sometimes doubled in length due to devlo’s running commentary. We found ourselves sifting through a wall of AI comments to find the one or two truly important suggestions. It felt like having a hyperactive intern – eager to help but pointing out the obvious along with the insightful. We occasionally responded with, “Thanks, devlo, we’ll consider that,” while secretly rolling our eyes at a comment about an extra newline. In short, devlo’s feedback was a mixed bag: very useful gems buried in a lot of well-intentioned noise.
GitHub Copilot (PR Reviews)
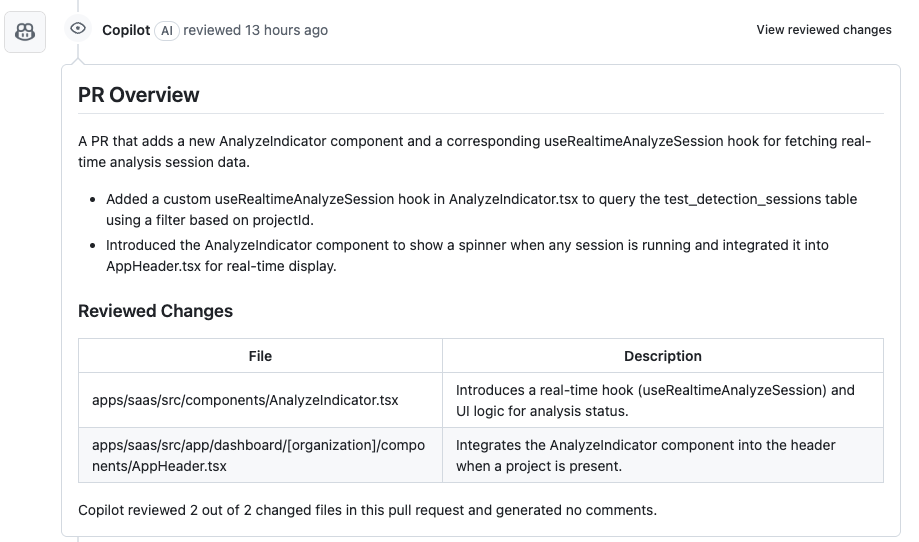
We also experimented with GitHub Copilot’s pull request review features (thanks to Microsoft’s integration of Copilot into the PR process). Unlike CodeRabbit and devlo, Copilot’s approach felt more like a gentle assistant than an overly eager reviewer. It typically produced fewer comments overall, focusing on only the most relevant points. In fact, its hallmark was delivering an excellent summary of the PR. For each pull request, Copilot would generate a succinct description of what changed – highlighting key modifications (e.g. “Added new validation for email input in UserForm component” or “Refactored the authentication middleware in the Python app”). This summary was pure gold for quickly understanding a large PR without reading every line.
However, when it came to detailed line-by-line feedback, Copilot was relatively quiet. It flagged only obvious issues or important discussions, leaving the nitpicks aside. This minimalist approach meant less noise, but also that Copilot might overlook some specific improvements that other tools would comment on. We also encountered automation challenges with Copilot. Being a new feature, it wasn’t as straightforward to integrate into our existing workflow – sometimes the PR summary generation felt a bit flaky to trigger automatically, and we had to manually invoke it. In one case, Copilot simply refused to comment on a PR in our monorepo, possibly confused by the multi-package diff. It’s clear this feature is still evolving. In summary: GitHub Copilot acted as a high-level PR assistant, great for summaries and light feedback, but not (yet) a comprehensive reviewer. We loved the summaries, but we couldn’t rely on Copilot alone for thorough code critique.
Ellipsis (YC W24)
Ellipsis was ultimately the best performer in our tests. Right out of the gate, Ellipsis’s feedback quality was impressive. It seemed to filter out unhelpful suggestions and avoid commenting just for the sake of it. When Ellipsis left a comment, it was usually on point – either identifying a potential bug, a logic oversight, or a meaningful improvement. For example, Ellipsis caught a tricky state management bug in our React app that none of the other AI tools (nor one of our humans!) caught initially. That earned it some real street cred with the team.
We also noticed that Ellipsis adapted to our feedback and guidelines over time. We had a few custom rules (like allowing certain TODO comments, or using specific TypeScript utility types) that initially triggered some comments from Ellipsis. But after we dismissed a couple of those and gave feedback, Ellipsis learned – subsequent PRs saw fewer of those irrelevant comments. It was almost as if it was tuning itself to our codebase’s personality. The tool also respects the project’s style guide strongly (it is capable of enforcing conventions like the others) but does so judiciously, without beating a dead horse.
The comment quality was uniformly high. Ellipsis’s comments read like a seasoned developer’s review: clear, concise, and with context. Instead of just “This is wrong,” it would say “This check will fail for empty arrays – consider handling that case to avoid a runtime error.” That kind of guidance is invaluable. It even provided occasional links to documentation or references when pointing out less obvious issues (like a security suggestion for an Express.js middleware).
It’s probably no surprise that by the end of our testing, Ellipsis stood out as our favorite. It struck the best balance between thoroughness and signal-to-noise. In the next section, we’ll dive a bit more into why Ellipsis earned a permanent spot in our workflow.
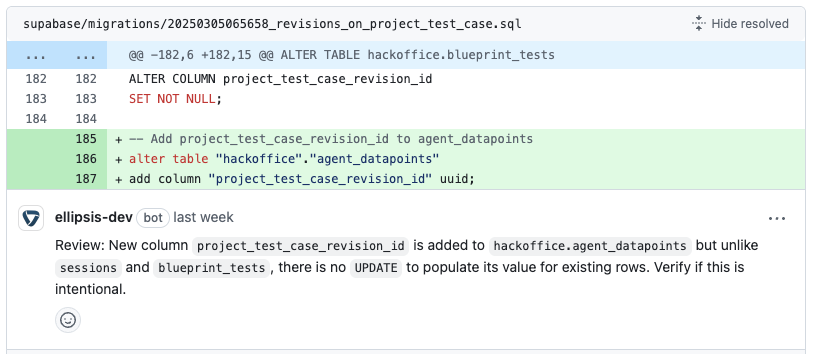
The Favorite: Why Ellipsis Stood Out
After weeks of dogfooding these AI tools, Ellipsis (YC W24) emerged as the clear favorite for our team. So, what made Ellipsis shine brighter than the rest?
1. Focused Reviews: Ellipsis has an almost human-like judgment on what’s important. It doesn’t bother us with trivial style points if our existing linters or formatters already handle them. Instead, it hones in on things that impact bug risk, logic, or maintainability. One developer noted, “Ellipsis’s comments feel like they came from a tech lead, not a lintern” – by which he meant a linter turned up to 11. We appreciated that it wasn’t trying to prove it read our code by commenting on every line; it spoke up only when it had something meaningful to say.
2. Adaptability: Perhaps the most impressive aspect was how Ellipsis learned from our interactions. We have a unique mix of frontend (React + ShadCN/Tailwind) and backend (Python FastAPI) code. Early on, we gave Ellipsis feedback by dismissing a couple of comments (e.g., it suggested a different Tailwind class usage that we decided against). To our surprise, similar suggestions didn’t appear in later reviews. It felt like training a smart junior dev: once we said “hey, in our repo we do XYZ this way,” Ellipsis remembered. This adaptability extended to following our coding guidelines. By feeding it our repo’s docs or simply through continued use, it started enforcing our specific style guide – not just generic best practices.
3. Quality of Feedback: The feedback from Ellipsis wasn’t just accurate – it was actionable and well-articulated. Comments often included reasoning or even pseudo-code for a fix. For example, in a PR refactoring our authentication logic, Ellipsis pointed out a potential race condition and suggested using an async lock, with a short code snippet to illustrate. It didn’t just say “possible bug here”; it told us the what and the why. This level of detail made the reviews much more useful. Team members learned from these AI comments instead of just feeling like they had to appease a bot.
4. Workflow Improvement: With Ellipsis in our GitHub workflow, we actually found our PRs getting merged faster and with more confidence. It acts like a tireless first-pass reviewer: catching things early that might otherwise lead to back-and-forth in code review. Human reviewers on our team could then focus more on design decisions and less on combing through for small bugs or style issues – we started trusting Ellipsis to handle a lot of that. It’s not perfect (we did occasionally disagree with a suggestion), but because it so rarely cried wolf, we paid attention when it spoke up. In a humorous twist, one teammate joked that Ellipsis deserved an “Employee of the Month” award, if only it had a GitHub profile picture to put on the plaque.
In summary, Ellipsis won us over by being consistently helpful, low-noise, and responsive to our needs. It felt like having an experienced developer assistant who knows our codebase and gets better every sprint. This dramatically improved our code review process – saving time and even catching a few issues that might have slipped through. We’ve decided to keep Ellipsis around as a permanent member of our PR review rotation (though we’re still waiting for it to start bringing donuts to the stand-up meeting ).
Honorable Mentions
Our experiment focused on CodeRabbit, devlo, GitHub Copilot, and Ellipsis (YC W24), but there are plenty of other AI-powered PR review tools out there. Do you know a better one? let us know!
Conclusion
In the end, introducing AI into our code review process proved to be a net positive. We caught issues we might have missed, saved senior developers some time, and even learned a few best practices along the way. The key was finding the right balance: using the AI feedback as a guide, not gospel. Human reviewers still have the final say, but now they have a helpful AI sidekick watching their back.
In all seriousness, our experience showed us that AI’s role in code review is like a competent junior developer: it speeds things up, asks good questions, and yes, sometimes it really needs a coffee break (looking at you, devlo, with those 117 comments on a 5-file PR).
