







Introduction
QA.tech aims to develop an AI-powered web agent capable of evaluating websites in a manner similar to human testers. Given a natural language instruction describing a test case, the AI agent autonomously navigates through websites, simultaneously identifying and documenting potential bugs and issues it encounters.
I am Alexandra Hotti and I hold a PhD in Machine Learning. At QA.tech I train and evaluate models, if you want to discuss – join our Discord.
The Problem
To train an agent to complete tasks on a website, we first need a standardized format to represent the websites. We record each website as a graph, similar to a sitemap, consisting of pages and the possible interactable elements (actions) available on each state of the page. A key challenge lies in creating unique and consistent representations for these actions to ensure that we do not record duplicate actions in the graph. For example, the “log in” button on Site X should be identifiable as the same action, even if the page undergoes changes, such as when dark mode is enabled or a dropdown menu is opened.
Creating Action Identifiers
MD5 Hashing
As an initial approach for creating unique action identifiers, we explored a non-Machine Learning method based on page screenshots and hashing. For each interactable element on the page, we defined an action context—the element and some neighborhood surrounding it—and captured a screenshot of this portion of the page. The unique identifier was generated by encoding and concatenating two components: the screenshot of the action context and the element’s relative position within that context, both hashed using MD5.
However, this approach had a drawback: any change within the action context—such as when a nearby form is filled in or the target button is highlighted—resulted in the same action receiving a different hash.
Contrastive Learning
Due to the limitations of the hashing approach, we chose to focus on learning meaningful representations of actions rather than creating unique identifiers for them. The goal was to learn representations where the same action would be positioned closely in an embedding space, even when changes occurred on the page.
Vision Based Approach
To obtain meaningful embeddings, we opted for a contrastive learning approach. To learn these embeddings, we fine-tuned a Dual Attention Vision Transformer (DaViT), which processed screenshots with overlaid bounding boxes around the target action elements.
We employed an active learning approach to construct our dataset. With access to approximately half a million pages, our goal was to extract a useful subset for training. Initially, we selected 2,000 action pairs. Positive pairs were defined as elements sharing the same encoding from a previous hashing method. Negative pairs were randomly sampled from the same website. After training an initial model, we significantly improved performance. We did this by expanding the dataset with about 3,000 challenging negative examples. Specifically, pairs of interactive elements that were incorrectly assigned highly similar embeddings.
This purely vision-based approach performed well on the majority of pages in our dataset. But it tended to become overly focused on the position of the target action element within the screenshot. For instance, in the figure below, the target action element is the button inside the bounding box for contacting David. When comparing the embeddings generated from two screenshots—one where David is positioned on the lower left and another where he is centered at the top—the embeddings exhibit a large L2 distance of 0.96, indicating that the model incorrectly considers them as a negative pair.
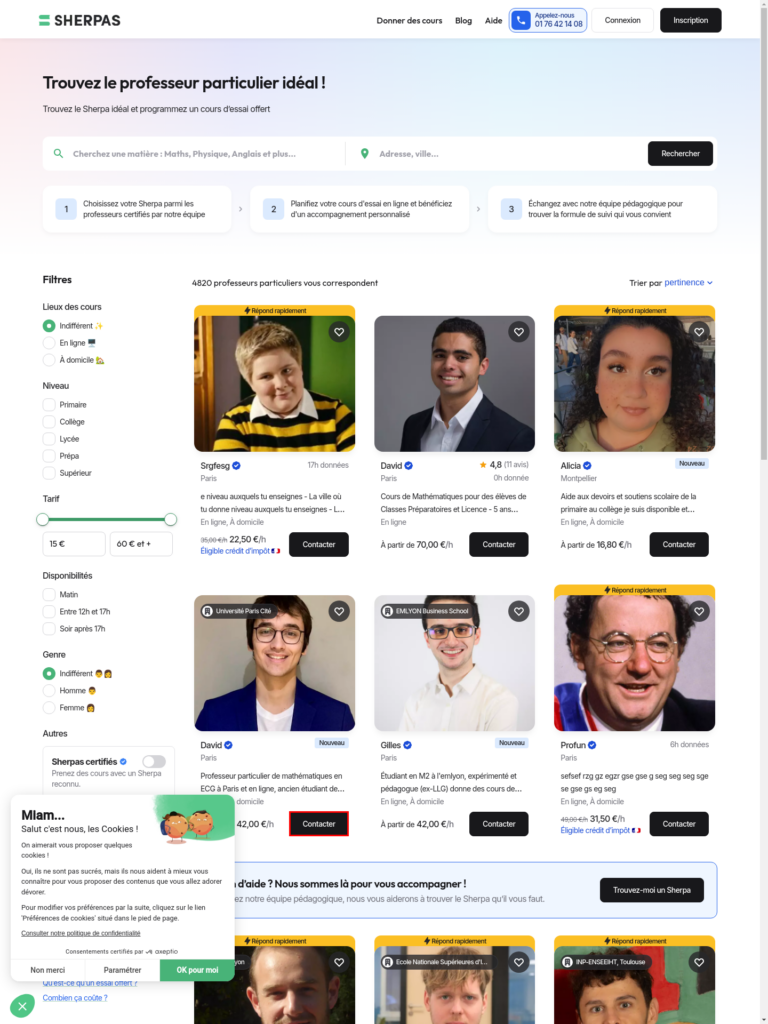
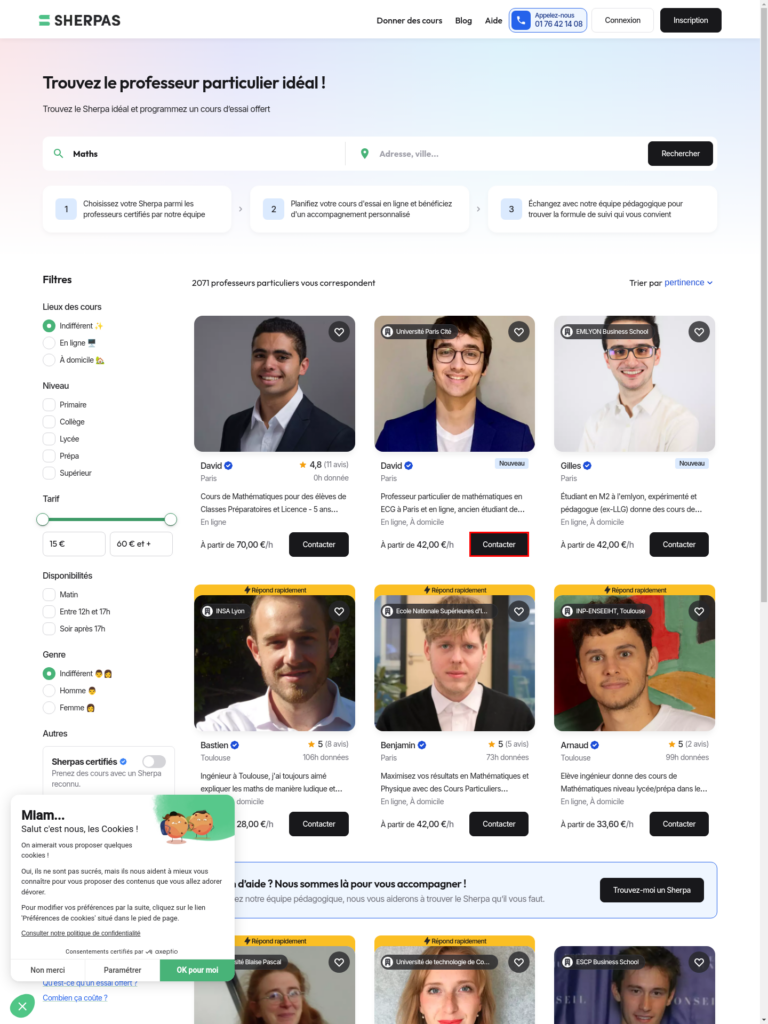
Figure 1: Screenshots showing the target action overlaid with bounding boxes, positioned at two different locations on the screen.
In the figure below, the screenshots on the left and right display two different actions which are located in the exact same position within the screenshots. Despite the differences in the text inside the bounding boxes, the position-focused model produces embeddings with an L2 distance of only 0.0049. This indicates that it almost considers them identical.
Figure 2: Screenshots showing two different actions located in the exact same position on the screen.
Combining Vision and HTML
This is the class we used to train the model, it is based on the SiameseNetwork class
class HTMLSiameseNetwork(nn.Module, PyTorchModelHubMixin):
def __init__(self, model_name='google/flan-t5-large', mean_pool = False):
super(HTMLSiameseNetwork, self).__init__()
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.mean_pool = mean_pool
self.html_tokenizer = T5Tokenizer.from_pretrained(model_name)
self.html_encoder = T5Model.from_pretrained(model_name)
html_embedding_dim = 1024
self.davit = create_model(
"davit_small.msft_in1k", pretrained=True, num_classes=0
)
self.image_fc = nn.Sequential(
nn.Linear(self.davit.num_features, 256),
nn.ReLU(inplace=True),
nn.Dropout(0.2),
nn.Linear(256, 128),
)
self.html_fc = nn.Sequential(
nn.Linear(html_embedding_dim, 512),
nn.ReLU(inplace=True),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.ReLU(inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 128),
nn.ReLU(inplace=True),
nn.Dropout(0.3),
nn.Linear(128, 128),
)
self.combined_fc = nn.Sequential(
nn.Linear(256, 256),
nn.ReLU(inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 128),
)
def embed_html(self, html):
inputs = self.html_tokenizer(html, return_tensors='pt', padding=True, truncation=True, max_length=512)
inputs = {key: val.to(self.device) for key, val in inputs.items()}
outputs = self.html_encoder.encoder(input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], return_dict=True)
if self.mean_pool:
html_embedding = torch.mean(outputs.last_hidden_state, dim=1)
else:
html_embedding = outputs.last_hidden_state[:, 0, :]
html_embedding = self.html_fc(html_embedding)
return html_embedding
def embed_image(self, img):
img_embedding = self.davit(img)
img_embedding = self.image_fc(img_embedding)
return img_embedding
def forward_one(self, img, html):
img_embedding = self.embed_image(img)
html_embedding = self.embed_html(html)
combined_embedding = torch.cat((img_embedding, html_embedding), dim=1)
combined_embedding = self.combined_fc(combined_embedding)
return combined_embedding
def forward(self, img1, img2, html1, html2):
embedding1 = self.forward_one(img1, html1)
embedding2 = self.forward_one(img2, html2)
return embedding1, embedding2We hypothesized that the vision-based model struggled to interpret the textual content on the page. And that our initial image-resizing process may have exacerbated this issue by making the model overly reliant on the spatial positioning of elements. To address this, we enhanced the model by incorporating both screenshots with overlayed bounding boxes and the HTML of the target action elements. Given the success of the Text-to-Text Transfer Transformer (T5) in previous works, we utilized Flan-T5-large to embed the HTML. By incorporating HTML, the model’s overall performance improves, accurately assigning the action pair in Figure 1 embeddings with an L2 distance of 0.000141, while the pair in Figure 2 is assigned a distance of 1.40.
Conclusion
Our journey from MD5 hashing to contrastive learning, and ultimately to combining vision with HTML, has significantly improved the identifiability of web actions. While the vision-based model struggled on its own, incorporating the HTML embeddings helped overcome these limitations. As a result, the action embedding model now accurately differentiates between actions. Even when page layouts or element positions change. This advancement brings us closer to developing an AI-powered web agent capable of evaluating websites with the precision of a human tester.
If you’re ready to see how this technology can enhance your web app testing, from identifying complex bugs to automating repetitive tasks , feel free to contact us or sign up for free here.
In-Depth Reading
Interested in learning more about how AI can improve end-to-end testing from a broader perspective? Check out this article on how contrastive learning helps AI models distinguish visually similar elements. It offers a general overview of how AI is changing QA processes, and overcoming certain UI challenges in automated AI-driven E2E-testing.
